Deep Convolutional GANs (DCGANs)
Before diving into Deep Convolutional GANs (DCGANs), it is highly recommended to have a solid understanding of Vanilla GANs and their underlying principles. If you are new to GANs or haven’t explored Vanilla GANs in detail, it is strongly advised to read the previous post titled “Understanding Vanilla GANs: Theory and Implementation” before proceeding with DCGANs. Vanilla GANs provide a foundational understanding of the core concepts and training dynamics of generative adversarial networks, which will make it easier to grasp the more advanced concepts and techniques used in DCGANs.
DCGANs, introduced by Radford et al. in the paper “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks,” are an extension of the Vanilla GAN architecture that incorporates convolutional layers. DCGANs have been shown to generate higher-quality images with more stable training compared to Vanilla GANs.
DCGAN Generator
The generator in a DCGAN uses transposed convolutional layers (also known as deconvolutional layers) to upsample the latent vector and generate images. The architecture typically consists of multiple transposed convolutional layers with increasing output channels, followed by batch normalization and activation functions (e.g., ReLU).
Here’s an example of a DCGAN generator implemented in PyTorch:
class Generator(nn.Module):
def __init__(self, latent_dim, channels=3, img_size=64):
super(Generator, self).__init__()
def deconvolution_block(in_channels, out_channels, kernel_size, stride,
padding, bn=True):
block = [nn.ConvTranspose2d(in_channels,
out_channels,
kernel_size,
stride,
padding,
bias=False)]
if bn:
block.append(nn.BatchNorm2d(out_channels, 0.8))
block.extend([
nn.ReLU(inplace=True),
nn.Dropout2d(0.25)
])
return nn.Sequential(*block)
self.conv_blocks = nn.Sequential(
deconvolution_block(latent_dim, img_size * 8, 4, 1, 0),
deconvolution_block(img_size * 8, img_size * 4, 4, 2, 1),
deconvolution_block(img_size * 4, img_size * 2, 4, 2, 1),
deconvolution_block(img_size * 2, img_size, 4, 2, 1),
nn.ConvTranspose2d(img_size, channels, 4, stride=2, padding=1),
nn.Tanh()
)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.ConvTranspose2d):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
def forward(self, x):
img = self.conv_blocks(x)
return img
The generator takes a latent vector z as input and passes it through a linear layer (self.l1) to increase its dimensionality. The output is then reshaped and passed through a series of transposed convolutional blocks (self.conv_blocks) to generate the final image. The output of the generator is a generated image with the specified number of channels (e.g., 3 for RGB images) and size.
DCGAN Discriminator
The discriminator in a DCGAN uses convolutional layers to downsample the input image and predict whether it is real or generated. The architecture typically consists of multiple convolutional layers with increasing channels, followed by batch normalization and activation functions (e.g., LeakyReLU).
Here’s an example of a DCGAN discriminator implemented in PyTorch:
class Discriminator(nn.Module):
def __init__(self, channels=3, img_size=64):
super(Discriminator, self).__init__()
def discriminator_block(in_filters, out_filters, bn=True):
block = [nn.Conv2d(in_filters, out_filters, 4, 2, 1)]
if bn:
block.append(nn.BatchNorm2d(out_filters, 0.8))
block.extend([
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.25)
])
return nn.Sequential(*block)
self.model = nn.Sequential(
discriminator_block(channels, img_size, bn=False),
discriminator_block(img_size, img_size * 2),
discriminator_block(img_size * 2, img_size * 4),
discriminator_block(img_size * 4, img_size * 8),
)
ds_size = img_size // 2 ** 4
self.flatten = nn.Flatten()
self.adv_layer = nn.Linear(img_size * 8 * ds_size ** 2, 1)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Conv2d):
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.Linear):
nn.init.xavier_uniform_(module.weight)
module.bias.data.zero_()
def forward(self, img):
out = self.model(img)
out = self.flatten(out)
validity = self.adv_layer(out)
return validity
The discriminator takes an image as input and passes it through a series of convolutional blocks (self.model) to extract features and downsample the image. The output of the convolutional blocks is flattened and passed through a linear layer (self.adv_layer) to produce a single value. In this implementation, we are going to omit the sigmoid activation function in the final layer of the discriminator. Instead, we will directly output the logits (raw values) from the linear layer. The reason for this is that we will be using the BCEWithLogitsLoss function later during training, which combines a sigmoid activation and binary cross-entropy loss in a numerically stable way. By omitting the sigmoid activation in the discriminator’s output layer, we can directly pass the logits to the BCEWithLogitsLoss function for computing the loss.
DCGANs Loss Function
The loss functions used in DCGANs are similar to those used in Vanilla GANs. The main objective is to train the discriminator to correctly classify real images as real (label = 1) and generated images as fake (label = 0), while the generator aims to fool the discriminator into classifying its generated images as real (label = 1).
For a more detailed explanation of the loss functions and the training process, please refer to the previous post “Understanding Vanilla GANs: Theory and Implementation.” Here’s a brief summary of the key points:
The discriminator loss consists of two components: the loss for real images and the loss for fake images.
- For real images, we want
D(real_images) = 1. The discriminator should classify real images with a label of 1, indicating that they are real. - For fake images generated by the generator, we want
D(fake_images) = 0. The discriminator should classify the generated images with a label of 0, indicating that they are fake.
The generator’s goal is to fool the discriminator into classifying its generated images as real. Therefore, the generator aims to get D(fake_images) = 1. In the generator loss, the labels are flipped to represent that the generator is trying to make the discriminator believe that the generated images are real.
def generator_loss(fake_logits):
""" Generator loss, takes the fake scores as inputs. """
# Create labels for the fake images
fake_labels = torch.ones_like(fake_logits)
# Calculate the binary cross-entropy loss
criterion = nn.BCEWithLogitsLoss()
loss = criterion(fake_logits, fake_labels)
return loss
def discriminator_loss(real_logits, fake_logits):
""" Discriminator loss, takes the fake and real logits as inputs. """
# Create labels for the real and fake images
real_labels = torch.ones_like(real_logits) # No label smoothing
fake_labels = torch.zeros_like(fake_logits)
# Calculate the binary cross-entropy loss for real and fake images
criterion = nn.BCEWithLogitsLoss()
real_loss = criterion(real_logits, real_labels)
fake_loss = criterion(fake_logits, fake_labels)
# Combine the losses
loss = real_loss + fake_loss
return loss
Training DCGANs
At its core, the training objective of DCGANs remains the same as Vanilla GANs: we want to train the generator to produce realistic images that can fool the discriminator, while simultaneously training the discriminator to accurately distinguish between real and generated images. It’s like a high-stakes game of cat and mouse, where the generator is constantly trying to outsmart the discriminator, and the discriminator is always on the lookout for any signs of deception.
However, DCGANs introduce a few clever techniques to stabilize the training process and improve the quality of the generated images. Here are some of the key differences:
- Batch Normalization: DCGANs employ batch normalization layers in both the generator and discriminator networks. Think of it as a way to keep the activations in check and prevent them from going wild during training. By normalizing the activations, we can reduce internal covariate shift and help stabilize the training process.
- Strided Convolutions: DCGANs leverage the power of strided convolutions in the discriminator and transposed convolutions in the generator. These techniques allow for efficient and spatially consistent feature learning, enabling the model to capture intricate patterns and details in the images.
- Noise Addition: DCGANs introduce a clever trick of adding random noise to the input images during the discriminator training. By injecting a bit of randomness, the discriminator becomes more robust and learns to focus on the overall structure and features of the images rather than relying on specific pixel patterns.
Now that we have a grasp of the theory behind DCGAN training, let’s take a closer look at the code and see how it all comes together.
def view_samples(epoch, samples):
fig, axes = plt.subplots(figsize=(14, 4), nrows=2, ncols=8, sharey=True, sharex=True)
for ax, img in zip(axes.flatten(), samples[epoch]):
img = img.detach().cpu().numpy()
img = np.transpose(img, (1, 2, 0))
img = ((img + 1) / 2 * 255).astype(np.uint8) # Rescale to pixel range (0-255)
ax.xaxis.set_visible(False)
ax.yaxis.set_visible(False)
ax.imshow(img)
plt.show()
def generator_step(generator, discriminator, g_optimizer, batch_size, latent_dim, device):
""" One training step of the generator. """
# Clear the gradients
g_optimizer.zero_grad()
# Generate fake images
noise = torch.randn(batch_size, latent_dim, 1, 1).to(device) # Move noise to the same device as the model
fake_images = generator(noise)
# Get the discriminator's predictions for the fake images
fake_logits = discriminator(fake_images)
# Calculate the generator loss
g_loss = generator_loss(fake_logits)
# Backpropagate the gradients
g_loss.backward()
# Update the generator's parameters
g_optimizer.step()
return g_loss.item()
def discriminator_step(discriminator, generator, d_optimizer, batch_size, latent_dim, real_images, device):
""" One training step of the discriminator. """
# Clear the gradients
d_optimizer.zero_grad()
# Get the discriminator's predictions for the real images
real_logits = discriminator(real_images)
# Generate fake images
noise = torch.randn(batch_size, latent_dim, 1, 1).to(device) # Move noise to the same device as the model
fake_images = generator(noise).detach() # Detach the fake images from the generator's graph
# Get the discriminator's predictions for the fake images
fake_logits = discriminator(fake_images)
# Calculate the discriminator loss
d_loss = discriminator_loss(real_logits, fake_logits)
# Backpropagate the gradients
d_loss.backward()
# Update the discriminator's parameters
d_optimizer.step()
return d_loss.item()
def training(model_G, model_D, z_size, g_optimizer, d_optimizer, generator_loss, discriminator_loss, g_scheduler, d_scheduler, nb_epochs, data_loader, print_every=50, device='cuda'):
num_epochs = nb_epochs
samples = []
losses = []
sample_size = 16
fixed_latent_vector = torch.randn(sample_size, z_size, 1, 1).float().to(device)
model_D.train()
model_G.train()
for epoch in range(num_epochs):
for batch_i, (real_images, _) in enumerate(data_loader):
real_images = real_images.to(device)
batch_size = real_images.size(0)
# Train the generator
g_loss = generator_step(model_G, model_D, g_optimizer, batch_size, z_size, device)
# Train the discriminator
d_loss = discriminator_step(model_D, model_G, d_optimizer, batch_size, z_size, real_images, device)
# Add noise to the input images
noise_factor = 0.1
noisy_real_images = real_images + noise_factor * torch.randn_like(real_images).to(device)
noisy_real_images = torch.clamp(noisy_real_images, 0, 1)
# Train the discriminator with noisy images
d_loss_noisy = discriminator_step(model_D, model_G, d_optimizer, batch_size, z_size, noisy_real_images, device)
# Get the discriminator's predictions for real and fake images
real_logits = model_D(real_images)
noise = torch.randn(batch_size, z_size, 1, 1).to(device)
fake_images = model_G(noise).detach()
fake_logits = model_D(fake_images)
# Use label smoothing
smooth_factor = 0.1
real_labels = torch.ones_like(real_logits).to(device) - smooth_factor
fake_labels = torch.zeros_like(fake_logits).to(device) + smooth_factor
d_loss_smooth = discriminator_loss(real_logits, fake_logits)
# Backpropagate the gradients for the discriminator with label smoothing
d_optimizer.zero_grad()
d_loss_smooth.backward()
d_optimizer.step()
if batch_i % print_every == 0:
# Append discriminator loss and generator loss
d = d_loss
g = g_loss
losses.append((d, g))
# Print discriminator and generator loss
time = str(datetime.now()).split('.')[0]
print(f'{time} | Epoch [{epoch+1}/{num_epochs}] | Batch {batch_i}/{len(data_loader)} | d_loss: {d:.4f} | g_loss: {g:.4f}')
# Call the schedulers after each epoch
g_scheduler.step()
d_scheduler.step()
# Display images during training
model_G.eval()
generated_images = model_G(fixed_latent_vector)
samples.append(generated_images)
view_samples(-1, samples)
model_G.train()
with open('train_samples.pkl', 'wb') as f:
pkl.dump(samples, f)
return losses, samples
The training function is where the magic happens. Let’s break it down:
- The training loop alternates between updating the generator and the discriminator using separate generator_step and discriminator_step functions. This allows for more flexibility in the training process and enables techniques like training the generator multiple times per discriminator update.
- Noise addition is applied to the input images during the discriminator training. A random noise factor is added to the real images, and the resulting noisy images are clamped to the valid range ([0, 1]). The discriminator is then trained on both the clean and noisy images, helping it become more robust.
- Label smoothing is applied to the discriminator’s target labels. Instead of using binary labels, the labels are smoothed using a smooth_factor. This regularizes the discriminator and prevents it from becoming too confident in its predictions.
- The generator and discriminator losses are computed using separate loss functions (generator_loss and discriminator_loss) that take into account the smoothed labels and the logits from the discriminator.
- Learning rate schedulers (g_scheduler and d_scheduler) are used to adjust the learning rates of the generator and discriminator optimizers during training. The schedulers are called after each epoch to update the learning rates based on a predefined schedule.
- Generated samples are displayed during training using the view_samples function, which visualizes the generated images at regular intervals. This allows for monitoring the progress and quality of the generated samples throughout the training process.
- The training samples are saved to a file using pickle for later analysis and visualization.
Compared to the training of Vanilla GANs, the DCGAN training incorporates techniques like noise addition, label smoothing, and separate generator and discriminator training steps to improve the stability and quality of the generated images.
Case Study: Generating Faces with DCGANs
In this case study, we will demonstrate how to use the Deep Convolutional GAN architecture to generate Faces using the CelebA dataset. We’ll go through the code step by step, explaining the hyperparameters, optimizers, and schedulers used in the training process.
Loading the MNIST Dataset
The first step is to load the CelebA dataset, a massive collection of celebrity faces that will serve as the training ground for our DCGAN. This dataset is widely used in computer vision and generative modeling tasks, offering a rich variety of facial features and attributes for our model to learn from.
To load the dataset, we’ll leverage the capabilities of PyTorch’s torchvision library, which provides convenient utilities for handling common datasets. Here’s a glimpse of the code:
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
# number of subprocesses to use for data loading
num_workers = 6
# how many samples per batch to load
batch_size = 64
# Define the transformations to be applied to the images
transform = transforms.Compose([
transforms.Resize((64, 64)), # Resize the images to 64x64
transforms.ToTensor(), # Convert the images to tensors
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # Normalize the images
])
# Set the path to your manually downloaded dataset directory
dataset_dir = 'processed_celeba_small/celeba'
# Create an instance of the ImageFolder dataset
train_data = datasets.ImageFolder(root=dataset_dir, transform=transform)
# Prepare the data loader
train_loader = DataLoader(train_data,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
drop_last=True,
pin_memory=False)
In this code snippet, we define a set of transformations to be applied to the images. We resize the images to a consistent size of 64x64 pixels, convert them to tensors, and normalize the pixel values to the range [-1, 1]. These transformations ensure that our DCGAN receives input images in a standardized format.
Next, we create an instance of the ImageFolder dataset, specifying the path to the CelebA dataset directory and the transformations to be applied. The ImageFolder dataset automatically organizes the images based on their directory structure, making it convenient to load and iterate over the data.
Finally, we create a data loader using the DataLoader class, which allows us to efficiently load the images in batches during training. We specify the batch size, enable shuffling to randomize the order of the images, and set the number of worker threads for parallel data loading.
With the CelebA dataset loaded and ready, we’re all set to dive into the exciting world of facial generation with DCGANs!
Creating the Models
Now that we have our dataset prepared, it’s time to define the architecture of our DCGAN. We’ll create two separate neural networks: the generator and the discriminator.
The generator network, denoted as G, takes random noise as input and learns to generate realistic facial images. It consists of a series of transposed convolutional layers that progressively upsample the noise vector into a full-sized image.
The discriminator network, represented as D, takes an image as input and learns to distinguish between real and generated images. It consists of a series of convolutional layers that downsample the image and extract relevant features.
Here’s a glimpse of how we create the models:
img_size = 64
z_size = 128
D = Discriminator(img_size= img_size)
G = Generator(latent_dim=z_size, img_size=img_size)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model_D = D.to(device)
model_G = G.to(device)
In this code snippet, we define the image size (img_size) and the size of the latent space (z_size). We then create instances of the discriminator (D) and generator (G) networks, specifying the appropriate sizes.
To take advantage of GPU acceleration, we move the models to the available CUDA device using model_D.to(device) and model_G.to(device). This ensures that the computations are performed on the GPU, enabling faster training.
With the models defined and ready to go, we’re one step closer to generating realistic facial images!.
Defining Optimizers and Schedulers
To train our DCGAN effectively, we need to define optimizers and learning rate schedulers for both the generator and discriminator networks.
Optimizers are responsible for updating the model parameters based on the gradients computed during backpropagation. In this case study, we’ll use the Adam optimizer, which is known for its good performance in deep learning tasks.
Learning rate schedulers allow us to dynamically adjust the learning rate during training. By reducing the learning rate at specific milestones, we can help the models converge to better solutions and avoid overshooting the optimal parameters.
Here’s how we define the optimizers and schedulers:
import torch.optim as optim
from torch.optim.lr_scheduler import MultiStepLR
# Optimizers
lr_G = 0.001
lr_D = 0.0001
num_epochs = 20
# Create optimizers for the discriminator and generator
d_optimizer = optim.Adam(model_D.parameters(), lr=lr_D, betas=(0.5, 0.999))
g_optimizer = optim.Adam(model_G.parameters(), lr=lr_G, betas=(0.5, 0.999))
# Learning rate scheduler
# Set the list of milestones when you want to adjust the learning rate
d_milestones = [15]
g_milestones = [3, 8, 15]
d_scheduler = MultiStepLR(d_optimizer, milestones=d_milestones, gamma=0.5)
g_scheduler = MultiStepLR(g_optimizer, milestones=g_milestones, gamma=0.5)
In this code snippet, we define the learning rates for the generator (lr_G) and discriminator (lr_D), as well as the number of training epochs (num_epochs).
We create instances of the Adam optimizer for both the discriminator (d_optimizer) and generator (g_optimizer), specifying the learning rates and beta values for momentum.
Next, we define the learning rate schedulers using the MultiStepLR class. We specify the milestones at which the learning rate should be adjusted and the scaling factor (gamma) by which the learning rate will be multiplied at each milestone.
With the optimizers and schedulers in place, we’re ready to embark on the training process and watch our DCGAN learn to generate realistic facial images!
Training the DCGAN
The moment of truth has arrived! It’s time to train our DCGAN and witness the magic unfold. The training process involves alternating between updating the discriminator and the generator, gradually improving their performance over multiple epochs.
Here’s a glimpse of the training code:
losses, samples = training(model_G, model_D, z_size,
g_optimizer, d_optimizer,
generator_loss, discriminator_loss,
g_scheduler, d_scheduler, num_epochs,
train_loader, print_every=50, device='cuda')
In this code snippet, we call the training function, passing in the necessary parameters such as the generator and discriminator models, optimizers, loss functions, schedulers, and the data loader.
During each training iteration, the following steps are performed:
- The discriminator is updated:
- A batch of real images is loaded from the data loader.
- The discriminator is trained to distinguish between real and generated images.
- The discriminator loss is computed based on its ability to correctly classify real and fake images.
- The discriminator’s parameters are updated using backpropagation.
- The generator is updated:
- Random noise is sampled from the latent space.
- The generator uses the noise to generate fake images.
- The generated images are passed through the discriminator.
- The generator loss is computed based on the discriminator’s feedback.
- The generator’s parameters are updated using backpropagation.
- The losses and generated samples are recorded:
- The discriminator and generator losses are appended to the losses list for monitoring the training progress.
- At regular intervals (print_every), the current losses are printed to provide insights into the training dynamics.
- Generated samples are periodically saved to visualize the improvement of the DCGAN over time.
As the training progresses, the discriminator becomes better at distinguishing real from fake images, while the generator learns to generate increasingly realistic facial images that can fool the discriminator.
After the specified number of epochs, the training concludes, and we are left with a trained DCGAN capable of generating facial images!
Analyzing the Results
After training our DCGAN, it’s time to analyze the results and assess the quality of the generated facial images. Let’s take a closer look at the training losses and the progression of the generated faces throughout the training process.
Training Losses
The training losses provide valuable insights into the performance and convergence of our DCGAN during training. Let’s examine the plot of the discriminator and generator losses over the course of training.
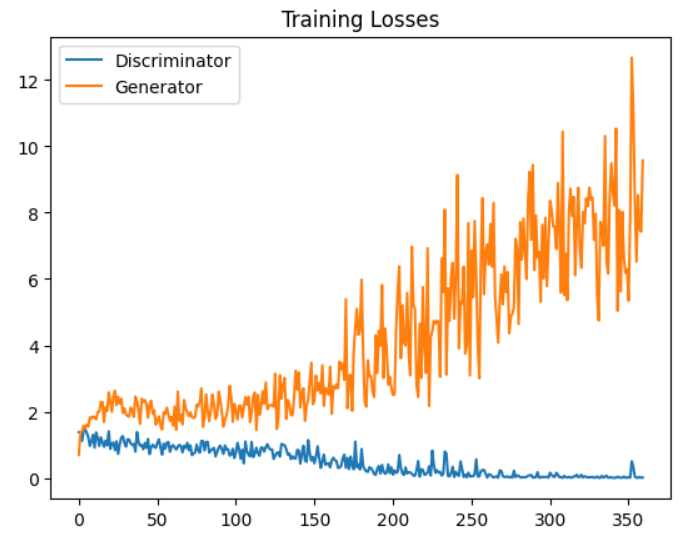
As we can see from the plot, both the discriminator and generator losses exhibit a oscillating pattern, which is characteristic of the adversarial training process in GANs. The discriminator loss (blue line) starts relatively low and gradually increases as the generator improves its ability to generate realistic faces. On the other hand, the generator loss (orange line) starts high and decreases over time as it learns to fool the discriminator more effectively.
It’s important to note that the goal is not necessarily to achieve the lowest possible losses, but rather to reach a state of equilibrium where the generator and discriminator are continuously challenging each other. The oscillating nature of the losses indicates that the adversarial game is being played effectively, with both networks improving together.
Progression of Generated Faces
Now, let’s dive into the most exciting part: analyzing the progression of the generated faces throughout the training process. By examining the generated images at different epochs, we can observe how the DCGAN’s ability to generate realistic faces evolves over time.

The image above showcases the generated faces by the DCGAN at intervals of 2 epochs, starting from epoch 2 and going up to epoch 20. Each row represents a specific epoch, displaying a grid of generated faces at that point in the training process.
Let’s break down the progression:
- Epoch 2: At the beginning of training, the generated faces are blurry, distorted, and lack coherent facial features. This is expected, as the generator is still learning to map the random noise to meaningful facial structures.
- Epochs 4-8: As training progresses, the generated faces start to exhibit more recognizable facial features. We can observe the emergence of eyes, noses, and mouths, although they may still appear distorted or misaligned.
- Epochs 10-14: The generated faces continue to improve in terms of realism and coherence. The facial features become more well-defined, and the overall structure of the faces starts to resemble real human faces more closely.
- Epochs 16-20: In the later stages of training, the DCGAN generates highly realistic and diverse facial images. The generated faces exhibit fine details, such as hair texture, skin tone variations, and even accessories like eyeglasses or earrings. The faces look convincingly real and are difficult to distinguish from genuine human faces.
It’s fascinating to witness the progressive improvement of the generated faces as the DCGAN learns to capture the intricate patterns and characteristics of real facial images. The ability to generate such high-quality faces demonstrates the power and effectiveness of the DCGAN architecture and training process.
Tips and Tricks
Congratulations on making it this far in your journey with DCGANs! By now, you’ve gained a solid understanding of the fundamental concepts and have successfully trained a DCGAN to generate realistic facial images. However, there’s always room for improvement and experimentation. In this section, I’ll share some valuable tips and tricks to help you take your DCGAN skills to the next level.
-
Experiment with Different Architectures While the DCGAN architecture we used in this case study has proven to be effective, don’t be afraid to experiment with different architectures and modifications. Try varying the number of layers, the size of the filters, or the activation functions used in the generator and discriminator networks. You might discover configurations that yield even better results or generate unique styles of faces.
-
Fine-tune the Hyperparameters Hyperparameters play a crucial role in the performance and stability of GANs. Experiment with different learning rates, batch sizes, and optimization algorithms to find the sweet spot for your specific task. Keep in mind that the optimal hyperparameters may vary depending on the dataset and the complexity of the images you’re working with.
-
Implement Gradient Clipping Gradient clipping is a technique that can help stabilize the training of GANs by limiting the magnitude of the gradients. By capping the gradients to a specific range, you can prevent them from exploding or vanishing, which can lead to training instability. PyTorch provides a convenient function called torch.nn.utils.clip_grad_norm_() that you can use to clip the gradients during training.
-
Use Different Loss Functions While binary cross-entropy loss is commonly used in GANs, there are other loss functions worth exploring. For example, the Wasserstein loss, used in Wasserstein GANs (WGANs), has shown promising results in terms of training stability and image quality. You can also experiment with different variations of the adversarial loss, such as the least squares loss or the hinge loss.
-
Implement Progressive Growing Progressive growing is a technique introduced in the Progressive Growing of GANs (ProGAN) paper. The idea is to start with a low-resolution generator and discriminator and gradually increase the resolution as training progresses. This approach allows the GAN to learn coarse features first and then progressively add finer details, leading to higher-quality images. Implementing progressive growing can be a bit more involved, but it’s worth exploring if you want to generate high-resolution faces.
-
Explore Different Datasets While the CelebA dataset is a popular choice for facial generation tasks, don’t limit yourself to just one dataset. Explore other facial image datasets like the FFHQ (Flickr-Faces-HQ) dataset or even create your own dataset by scraping images from the web. Experimenting with different datasets can help you assess the generalization capabilities of your DCGAN and identify potential biases or limitations.
-
Monitor and Visualize the Training Progress Regularly monitoring and visualizing the training progress is crucial for understanding the behavior of your DCGAN. Use tools like TensorBoard or Visdom to track the generator and discriminator losses, as well as other metrics like the Inception Score or the Fréchet Inception Distance (FID). Visualizing the generated images at different stages of training can also provide valuable insights into the quality and diversity of the generated faces.
-
Leverage Transfer Learning If you have limited computational resources or a small dataset, transfer learning can be a powerful technique to improve the quality of your generated faces. You can start with a pre-trained generator or discriminator from a different task or dataset and fine-tune it for your specific facial generation task. Transfer learning can help you achieve better results with fewer training iterations and less data.
-
Experiment with Conditional GANs Conditional GANs (cGANs) extend the basic GAN framework by incorporating additional information, such as class labels or attributes, into the generation process. By conditioning the generator and discriminator on specific attributes (e.g., hair color, gender, age), you can gain more control over the generated faces and create targeted variations. Exploring conditional GANs can open up new possibilities for facial generation and manipulation.
-
Stay Updated with the Latest Research The field of generative adversarial networks is rapidly evolving, with new techniques and architectures emerging regularly. Stay updated with the latest research papers, blog posts, and open-source implementations to keep yourself informed about the state-of-the-art methods in facial generation. Participating in online communities, attending conferences, and collaborating with other researchers can also provide valuable insights and inspire new ideas.
Remember, the key to mastering DCGANs and generating stunning facial images lies in experimentation, iteration, and continuous learning. Don’t be afraid to try out new ideas, make mistakes, and learn from them. With patience, persistence, and a curious mindset, you’ll be well on your way to becoming a DCGAN expert!
So, go forth and generate some mind-blowing faces that push the boundaries of what’s possible with generative models. The world of facial generation is yours to explore and conquer!
References:
- Radford, A., Metz, L., & Chintala, S. (2015). “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.” arXiv preprint arXiv:1511.06434. Link
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). “Generative Adversarial Networks.” arXiv preprint arXiv:1406.2661. Link
- Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). “Improved Techniques for Training GANs.” arXiv preprint arXiv:1606.03498. Link